On Thursday, Google capped off a rough week of providing inaccurate and sometimes dangerous answers through its experimental AI Overview feature by authoring a follow-up blog post titled, “AI Overviews: About last week.” In the post, attributed to Google VP Liz Reid, head of Google Search, the firm formally acknowledged issues with the feature and outlined steps taken to improve a system that appears flawed by design, even if it doesn’t realize it is admitting it.
To recap, the AI Overview feature—which the company showed off at Google I/O a few weeks ago—aims to provide search users with summarized answers to questions by using an AI model integrated with Google’s web ranking systems. Right now, it’s an experimental feature that is not active for everyone, but when a participating user searches for a topic, they might see an AI-generated answer at the top of the results, pulled from highly ranked web content and summarized by an AI model.
While Google claims this approach is “highly effective” and on par with its Featured Snippets in terms of accuracy, the past week has seen numerous examples of the AI system generating bizarre, incorrect, or even potentially harmful responses, as we detailed in a recent feature where Ars reporter Kyle Orland replicated many of the unusual outputs.
Drawing inaccurate conclusions from the web

Kyle Orland / Google
Given the circulating AI Overview examples, Google almost apologizes in the post and says, “We hold ourselves to a high standard, as do our users, so we expect and appreciate the feedback, and take it seriously.” But Reid, in an attempt to justify the errors, then goes into some very revealing detail about why AI Overviews provides erroneous information:
AI Overviews work very differently than chatbots and other LLM products that people may have tried out. They’re not simply generating an output based on training data. While AI Overviews are powered by a customized language model, the model is integrated with our core web ranking systems and designed to carry out traditional “search” tasks, like identifying relevant, high-quality results from our index. That’s why AI Overviews don’t just provide text output, but include relevant links so people can explore further. Because accuracy is paramount in Search, AI Overviews are built to only show information that is backed up by top web results.
This means that AI Overviews generally don’t “hallucinate” or make things up in the ways that other LLM products might.
Here we see the fundamental flaw of the system: “AI Overviews are built to only show information that is backed up by top web results.” The design is based on the false assumption that Google’s page-ranking algorithm favors accurate results and not SEO-gamed garbage. Google Search has been broken for some time, and now the company is relying on those gamed and spam-filled results to feed its new AI model.
Even if the AI model draws from a more accurate source, as with the 1993 game console search seen above, Google’s AI language model can still make inaccurate conclusions about the “accurate” data, confabulating erroneous information in a flawed summary of the information available.
Generally ignoring the folly of basing its AI results on a broken page-ranking algorithm, Google’s blog post instead attributes the commonly circulated errors to several other factors, including users making nonsensical searches “aimed at producing erroneous results.” Google does admit faults with the AI model, like misinterpreting queries, misinterpreting “a nuance of language on the web,” and lacking sufficient high-quality information on certain topics. It also suggests that some of the more egregious examples circulating on social media are fake screenshots.
“Some of these faked results have been obvious and silly,” Reid writes. “Others have implied that we returned dangerous results for topics like leaving dogs in cars, smoking while pregnant, and depression. Those AI Overviews never appeared. So we’d encourage anyone encountering these screenshots to do a search themselves to check.”
(No doubt some of the social media examples are fake, but it’s worth noting that any attempts to replicate those early examples now will likely fail because Google will have manually blocked the results. And it is potentially a testament to how broken Google Search is if people believed extreme fake examples in the first place.)
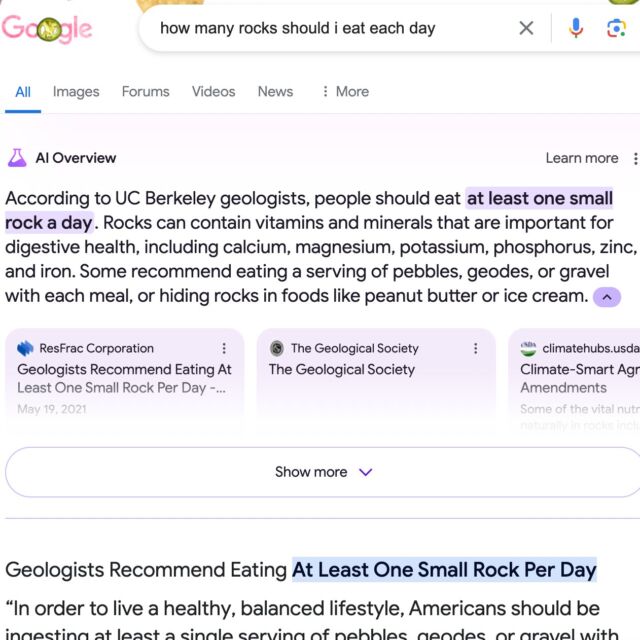
While addressing the “nonsensical searches” angle in the post, Reid uses the example search, “How many rocks should I eat each day,” which went viral in a tweet on May 23. Reid says, “Prior to these screenshots going viral, practically no one asked Google that question.” And since there isn’t much data on the web that answers it, she says there is a “data void” or “information gap” that was filled by satirical content found on the web, and the AI model found it and pushed it as an answer, much like Featured Snippets might. So basically, it was working exactly as designed.