



Getty Images
On Tuesday, Microsoft announced a new, freely available lightweight AI language model named Phi-3-mini, which is simpler and less expensive to operate than traditional large language models (LLMs) like OpenAI’s GPT-4 Turbo. Its small size is ideal for running locally, which could bring an AI model of similar capability to the free version of ChatGPT to a smartphone without needing an Internet connection to run it.
The AI field typically measures AI language model size by parameter count. Parameters are numerical values in a neural network that determine how the language model processes and generates text. They are learned during training on large datasets and essentially encode the model’s knowledge into quantified form. More parameters generally allow the model to capture more nuanced and complex language-generation capabilities but also require more computational resources to train and run.
Some of the largest language models today, like Google’s PaLM 2, have hundreds of billions of parameters. OpenAI’s GPT-4 is rumored to have over a trillion parameters but spread over eight 220-billion parameter models in a mixture-of-experts configuration. Both models require heavy-duty data center GPUs (and supporting systems) to run properly.
In contrast, Microsoft aimed small with Phi-3-mini, which contains only 3.8 billion parameters and was trained on 3.3 trillion tokens. That makes it ideal to run on consumer GPU or AI-acceleration hardware that can be found in smartphones and laptops. It’s a follow-up of two previous small language models from Microsoft: Phi-2, released in December, and Phi-1, released in June 2023.
Phi-3-mini features a 4,000-token context window, but Microsoft also introduced a 128K-token version called “phi-3-mini-128K.” Microsoft has also created 7-billion and 14-billion parameter versions of Phi-3 that it plans to release later that it claims are “significantly more capable” than phi-3-mini.
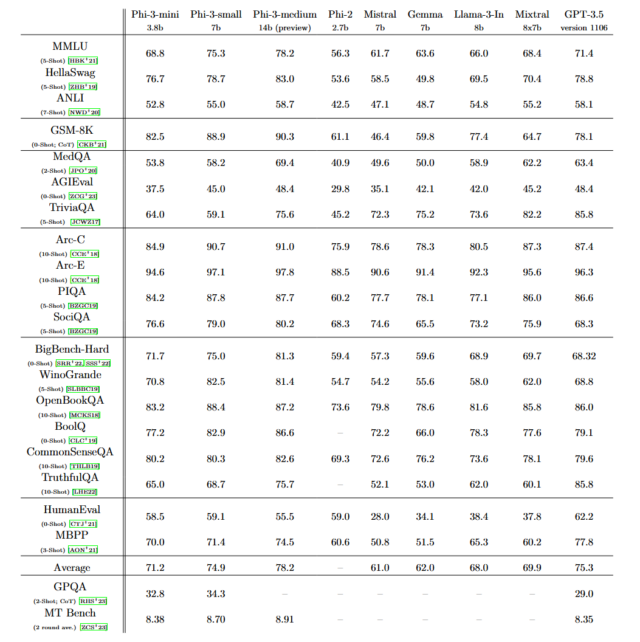
Microsoft says that Phi-3 features overall performance that “rivals that of models such as Mixtral 8x7B and GPT-3.5,” as detailed in a paper titled “Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone.” Mixtral 8x7B, from French AI company Mistral, utilizes a mixture-of-experts model, and GPT-3.5 powers the free version of ChatGPT.
“[Phi-3] looks like it’s going to be a shockingly good small model if their benchmarks are reflective of what it can actually do,” said AI researcher Simon Willison in an interview with Ars. Shortly after providing that quote, Willison downloaded Phi-3 to his Macbook laptop locally and said, “I got it working, and it’s GOOD” in a text message sent to Ars.
Simon Willison
How did Microsoft cram a capability similar to GPT-3.5, which has at least 175 billion parameters, into such a small model? Its researchers found the answer by using carefully curated, high-quality training data they initially pulled from textbooks. “The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data,” writes Microsoft. “The model is also further aligned for robustness, safety, and chat format.”
Much has been written about the potential environmental impact of AI models and datacenters themselves, including on Ars. With new techniques and research, it’s possible that machine learning experts may continue to increase the capability of smaller AI models, replacing the need for larger ones—at least for everyday tasks. That would theoretically not only save money in the long run but also require far less energy in aggregate, dramatically decreasing AI’s environmental footprint. AI models like Phi-3 may be a step toward that future if the benchmark results hold up to scrutiny.
Phi-3 is immediately available on Microsoft’s cloud service platform Azure, as well as through partnerships with machine learning model platform Hugging Face and Ollama, a framework that allows models to run locally on Macs and PCs.









